Indexing
In this note we will take a look at what are indexes, the different types of existing indices, and how they can be used in a given database. We will also take a look at B-trees.
Indexing
In large datasets with multiple entries, it can become very expensive to perform lookups using only the primary key. The solution for this is indexing: just like a book catalog in a library, an index catalogs entries according to an attribute or set of attributes. This attribute is called the search-key of the index.
An index file will consist of several index entries, which have the following aspect:
![]()
Fig.1: Index entry example
Index files are typically much shorter than the original file containing the data
There are two types of indexes (which we will go into deeper detail):
- Ordered Indices: search keys are stored in sorted order
- Hash Indices: search keys are distributed across buckets using hash functions
Ordered Indices
In ordered indices, index entries are stored in a file sorted by their search key value. We can then specify two types of ordered indices:
- Clustered Index: The order in this index specifies the sequential order in the data file
- Usually (but not always) the search key of this index corresponds to the primary key
- Non-Clustered Index: An index which specifies an order different from the one in the file
Dense Index File
In a dense index, there exists a index entry for every search-key value in the file.
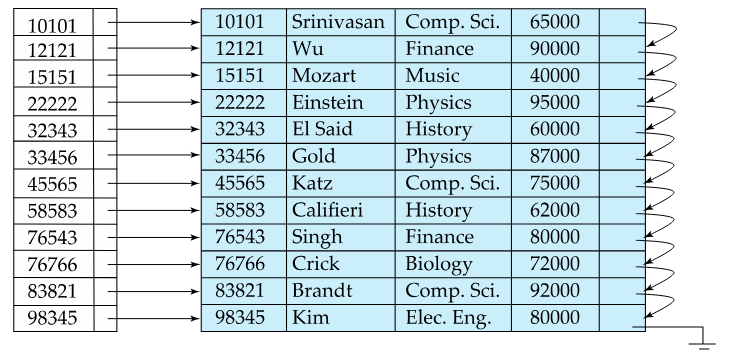
Fig.2: Dense index example (index on id)
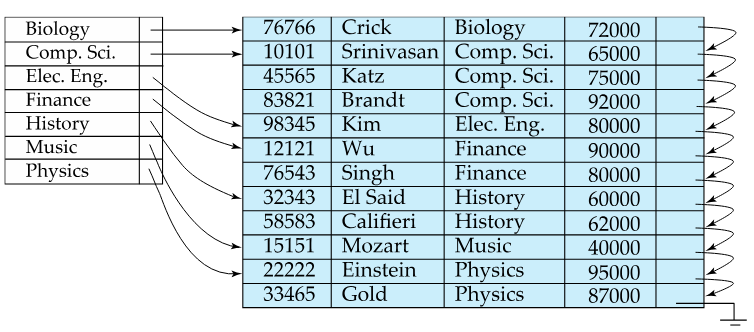
Fig.3: Another example of a dense index, this time on dept. name
Sparse Index Files
In sparse index files, the opposite happens: there is only index entries for some search-key values. This is only applicable when the records are sequentially ordered on the search-key:
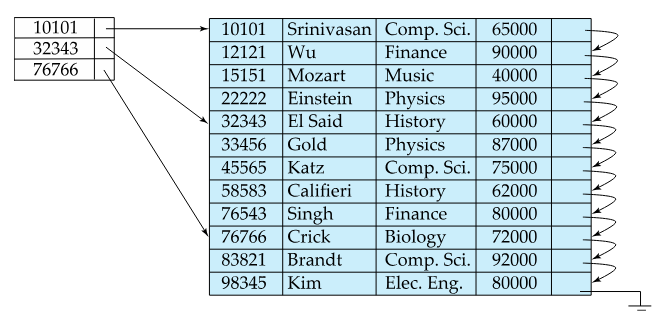
Fig.4: Sparse index example
Dense vs Sparse Indices
The main tradeoff that has to be considered when comparing dense and sparse indexes is choosing between speed and size:
- Dense indexes are faster than sparse indexes at doing lookups of entries
- Sparse indexes occupy less space than dense indexes
Clustered vs Non-Clustered Indices
Now that we have seen the differences between dense and sparse indices, we can correlate take the following conclusions:
- Non-Clustered Indices have to be dense indices. This is because sparse indices must be ordered on their particular search-key, and the records are only sequentially ordered according to clustered indices
- Sequential scan using a clustered index is efficient, as opposed to a non-clustered index where doing this is inefficient
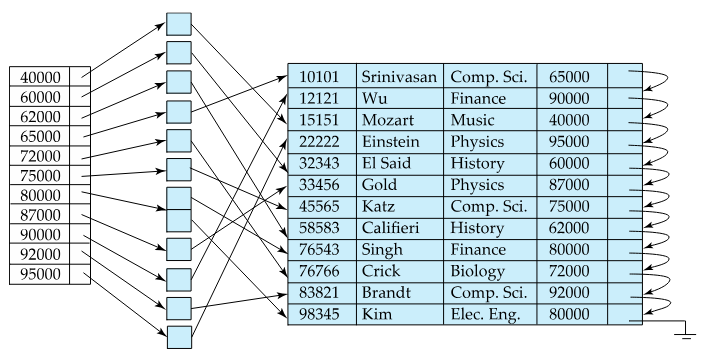
Fig.5: Non-clustered index example
B-Tree Indices
Ordered indices can also be of the B-tree format. A B-tree follows the following properties:
- All paths from root to leaf are the same length
- Each node that is not a root or a leaf has between and children
- A leaf node has between and values
- Special cases:
- If the root is not a leaf, it has at least two children
- If the root is the leaf (there are no other values nodes in the tree), it can have between and values
is a predefined value, that establishes how large is each B-Tree node
Up next is an example of a B-tree:
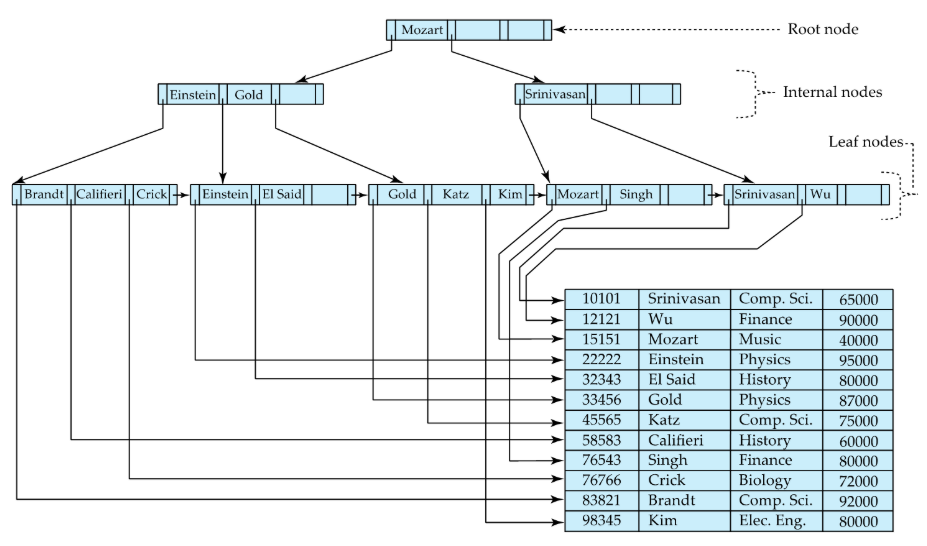
Fig.6: B-Tree example
B-Tree Node Structure
A typical node of a B-Tree is composed by several of the following two elements:
- Search-key values (K)
- Pointers to other nodes (children) or pointers to records (P)
These elements are then intercalated, and a node will have the following structure:
![]()
Fig.7: B-Tree node structure
Also, the search-keys in a node are structured, i.e.:
- K < K ... K < K
Leaf Nodes
Each leaf node has the following properties:
- P () points to a record/bucket of records with search-key value equal to K
- Pointer P points to the next leaf node (according to search-key order)
- If L and L are both leaf nodes, with , then all L's search-key values are than L's search-key values
Non-leaf Nodes
A good way to think about non-leaf nodes (root and internal nodes) is that they form a multilevel sparse index on leaf nodes.
Considering the example above of a node structure:
- All the search keys for which the pointer P points are K
- All the search keys pointed by P, with are K and K
- All the search keys pointed by P are K
Up next is an example of a B-Tree following these rules:
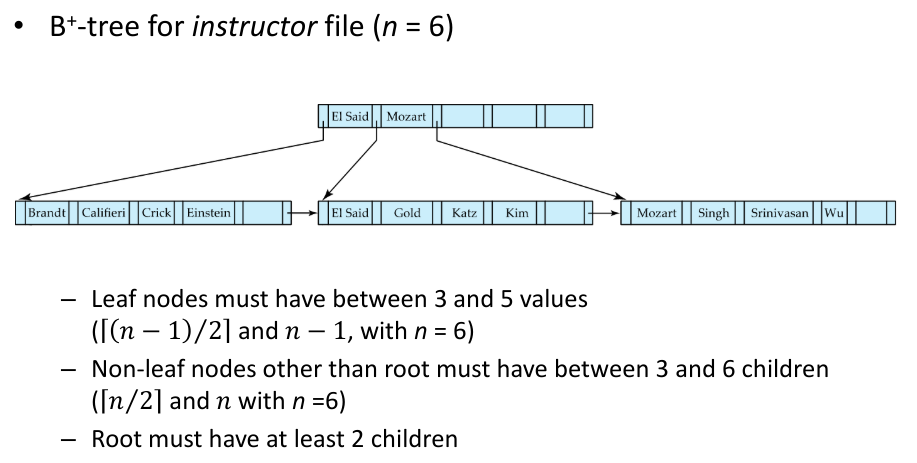
Fig.8: B-Tree structure example with n = 6
Observations about B-Trees
- Since nodes connect to each other, logically "close" nodes do not need to be physically stored next to each other (facilitates storing)
- B-Trees contain few levels, since each level exponentially stores more and more values (in relation to n):
- Level below root stores values
- Level below that stores values
- Etc...
- If there are 𝐾 search-key values in the file, the tree height is no more than thus searches can be conducted efficiently. ^ad65a1
- Because the index can be restructured in logarithmic time, insertions and deletions are efficient
Queries on B-Trees
Algorithm
The algorithm to find a value in a B-Tree is the following:
-
Starting on the root node:
- If there is such that , then follow pointer
- If there is such that , then follow pointer
- If no found that satisfies the last two properties, then follow the last pointer
-
Repeat this until a leaf node is reached
-
Once a leaf node is reached:
- If there is such that , then follow
- If there is no such , that means that doesn't exist in this index
Range Queries
To perform a range query (i.e., find all values that satisfy ), this is the algorithm:
- Perform a normal query on value , using the algorithm above.
- After finding , go through every value followed by it (using pointers to the next leaf node)
- Retrieve values from every pointer such that
- Stop upon finding the first such that , or go until the end
Query Performance
If we look closely at the algorithm used for queries in B-trees, we can clearly see that query time is directly affected by the height of tree* that, like we saw here, is equal to . In a real world implementation of a B-tree, is typically around 100; with , we have:
- At most nodes are accessed, which corresponds to only 4 nodes
- In a balanced binary tree, we wold have to traverse about 20 nodes
Updates on B-Trees
We will take a look at how to insert and delete values from B-trees.
Insertion
To insert a value into a B-tree, we assume that the record was already added to the file. Then we consider:
- to be the pointer to the record
- to be the search-key of that record
We then find the lead node where that record would be (with the current tree). If there is space in that leaf, we insert the pair into that leaf node. If not, we will need to split the leaf node:
Splitting a Leaf Node
The algorithm for inserting a value into a full leaf node is the following:
- Take the pairs (search-key, pointer) of the leaf node where we would insert , plus the pair , and place the first nodes in the original node, and the rest in a new node
- Let the new node be and the least key value in . Insert into the parent of the node being split
- If the parent node, split it too (and do this if its parent is full, etc.)
Up next are two examples of this:
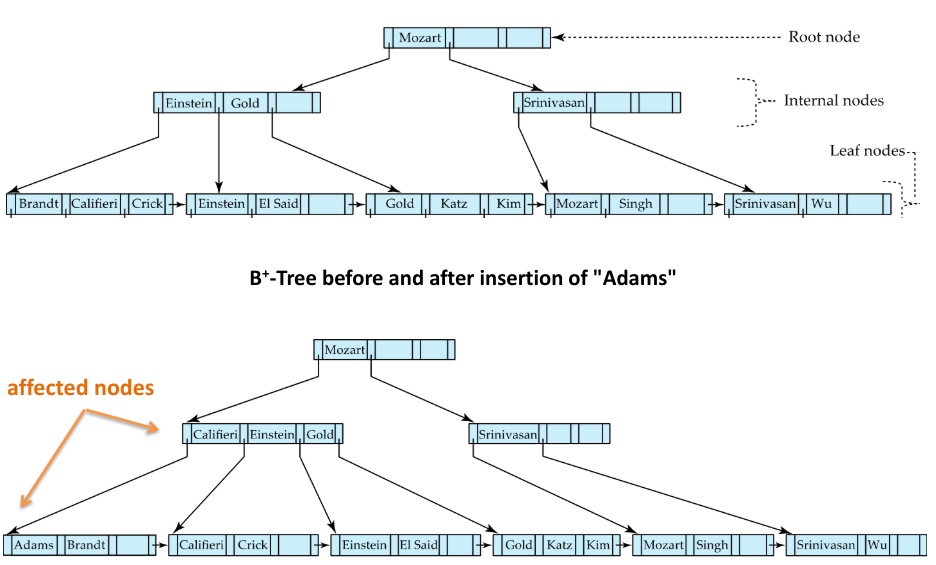
Fig.9: Example of a B-tree insertion
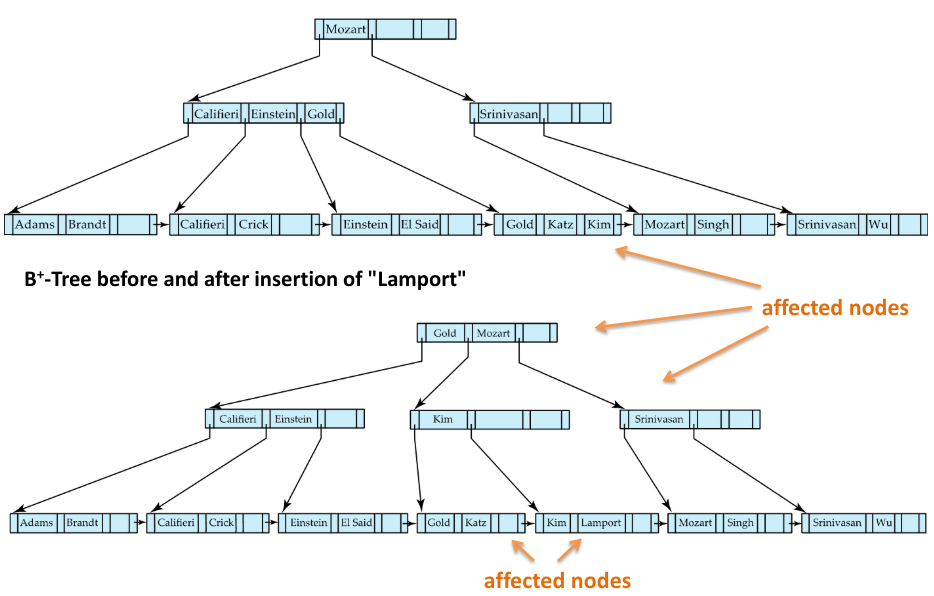
Fig.10: Another example of a B-tree insertion
Deletion
Just like in inserting a value into a B-tree, when deleting a value we assume we have already deleted the value; we then evaluate if the node has too few elements: if it does not, we leave it as is; if it does, we will have to perform some merges.
Let:
- be the pointer of the entry to be removed
- to be the search-key of the entry to be removed
If the node has too few entries, and if the node itself and its sibling fit into a single node, then we can merge the two nodes:
- Insert all the values into a single node (the one on the left) and delete the other node (the one on the right)
- In the parent node of the deleted node, delete the pair , being the pointer that pointed to the deleted node
- If the parent node also has too few entries, repeat the previous two steps recursively
Otherwise, if the node has too few entries due to the removal, but the entries in the node and a sibling do not fit into a single node, then redistribute pointers:
- Redistribute the pointers between the node and a sibling such that both have more than the minimum number of entries
- Update the corresponding search-key value in the parent of the node
The following three images show examples of deletions in B-trees:
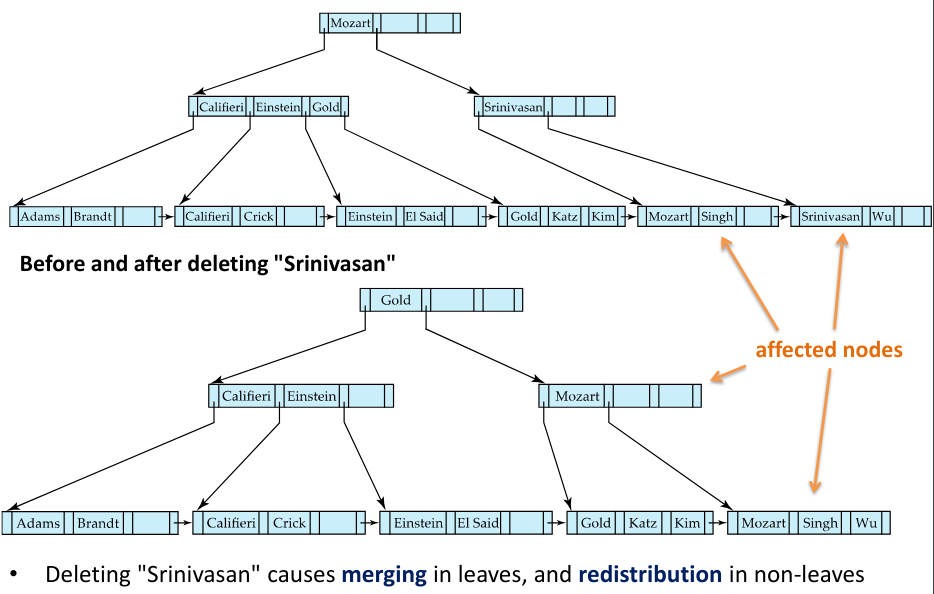
Fig.11: Example of a deletion in a B-tree
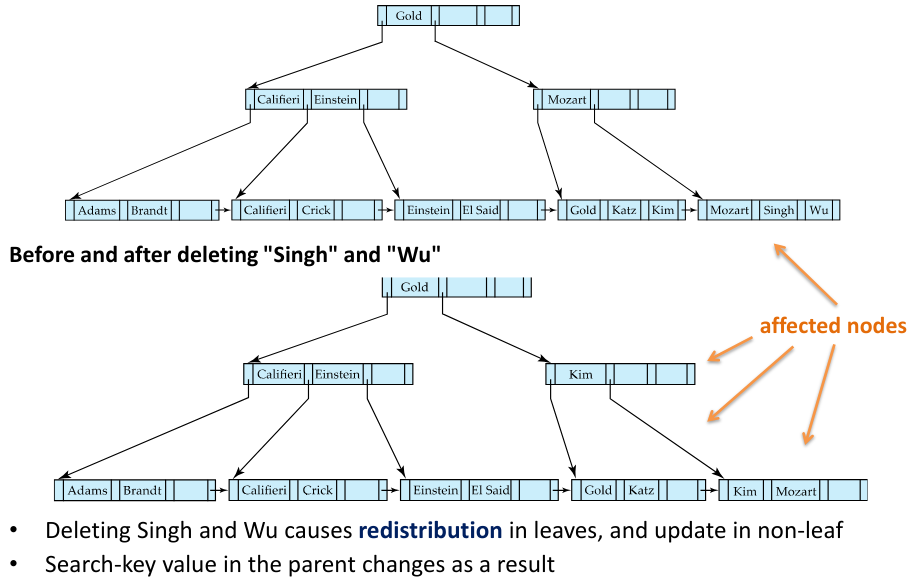
Fig.12: Example of a deletion in a B-tree
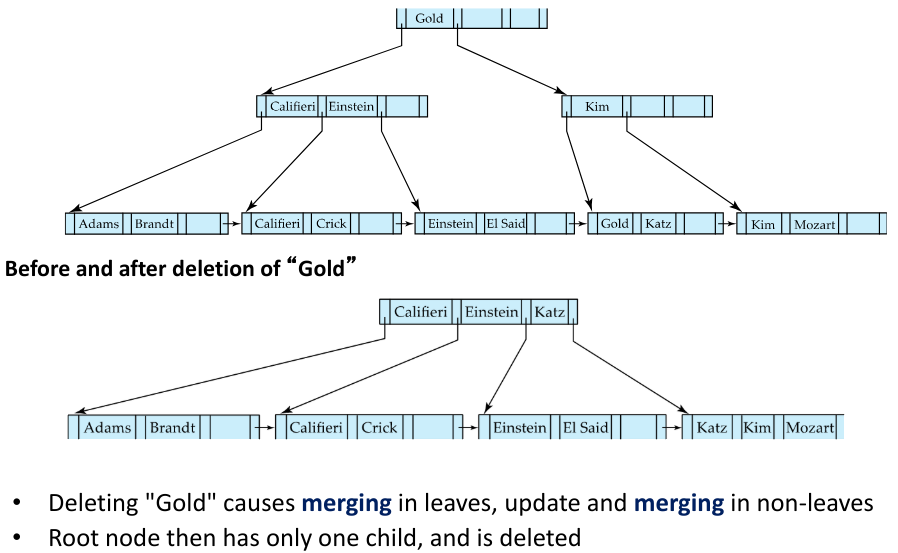
Fig.13: Example of a deletion in a B-tree
Update Cost
As we saw in the previous two chapters, in both insertions and deletions the total number of operations (splitting/merging nodes) it has to be done to complete these updates is directly related to the height of the tree. Therefore, we can conclude that, in the worst case, an update to a B-tree has the complexity:
However, this is in the worst case. In practice, splits/merges are rare, and inserts and deletes are very efficient.
B-tree File Organization
A B-tree with file organization has exactly the same structure has the B-tree we saw in the previous chapters, with the exception that leafs hold the records themselves, not pointers to the records. This has the advantage of helping keep data clustered; however, because size restrictions are still the same, and records occupy more space than pointers, leaf nodes can hold less records when compared with a B-tree with pointers.
Insertion and deletion are handled in the same way as a B-tree index
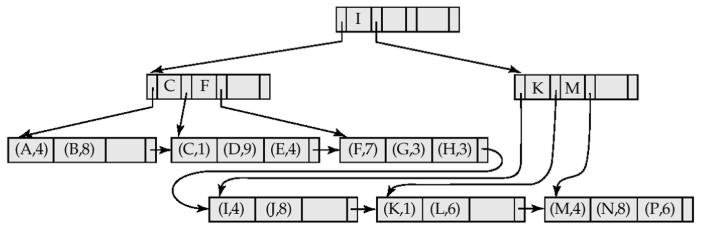
Fig.14: Example of a B-tree file organization