File Organization
In this note, we will take a closer look at different ways that database systems can organize its data, and the different record types that exist.
Records
Database are usually stored as a collection of files. In order for database systems to be able to read these files more efficiently, these files are divided in records. But what is the correct way of dividing/storing these records?
Record Types
Fixed-length records
In this approach:
- Each record has the same length
- Each file holds records of the same type
- Different files hold records of different relations
For this record type, we assume that the record length doesn't surpass disk block length
To organize records using this approach, we simply store block starting in byte :
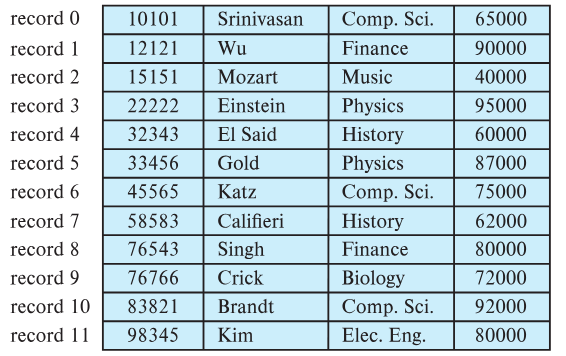
Fig.1: Fixed-length record table example
For deletion of records we have three alternatives:
- Move block , ->
- Move record to
- Do not move records, but keep a free records list
Variable-length records
There are several reasons for which databases need to use variable-length records:
- Storage of variable-length fields, like varchars (strings)
- Storage of different types of records in the same file
- Data types that allow repeatable fields
A variable-length record starts with fixed-size fields describing the variable-length fields (offset, length); these variable-length fields are stored later in the record.
Storing Large Objects
Typically stored in databases with clob/blob data type, these objects cannot be stored in typical records (because, as we saw, record size cannot surpass the length of a block). Therefore, there are three alternatives to store these type of objects:
- Store in a separate file in the file system
- Store in a file managed by the database management system
- Divide the data, and store each piece in tuples
Organization of Records in Files
Now that we have seen different ways of creating records, we will see how can we store and organize them inside the file they are stored on. There are five different alternatives:
- Heap - records can be placed anywhere in a file
- Sequential - records are placed in a sequential manner, based on value of search key
- Multitable Clustering File Organization - store records of different relations in the same table
- Hashing - calculate the hash function of the search key of a record - the output of this function will determine where in the file should the record be stored
- B+ tree - ordered storage even with inserts/deletes (more on this in this note #to-do)