Firewalls and IDS
In this note, we take a look at how do firewalls work, why we need them and potential benefits and issues with their usage. We also take a look at what is an IDS, and its differences to a firewall.
A firewall is a security mechanism that prevents unauthorized access and attacks to a local machine or local network. A firewall is usually placed between an untrusted network (for example, the Internet) and a trusted network that we want to protect (for example, and organization's LAN), acting as a barrier to only allow authorized traffic to pass through it.
Therefore, a firewall:
- Creates a perimeter defense
- Prevents illegal accesses/modifications from outside sources to internal state
- Mitigates DDOS attacks
- Is a way of enforcing access control policies in a centralized manner
One of the ways a firewall does all this is through packet filtering.
Packet Filtering
Packet filtering consists in analyzing all the traffic that passes through the machine that the firewall is running at, and allow some packets to go through, and others to be discarded. This filtering is decided according to the a set of rules, established in the firewall.
A general firewall rule will have the following format:
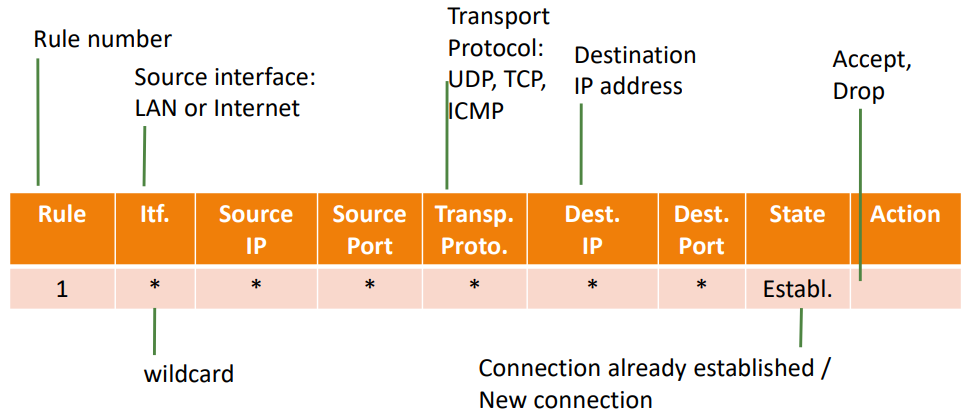
Fig.1: Structure of a firewall rule
Parameters:
- Rule Number: rule identifier
- Source Interface: identifies the interface from where the packet has come from (example: internet, LAN)
- Source IP: IP address of the sender of the packet
- Source Port: From which port in the sender was the packet sent
- Transport Protocol: What protocol was used to transmit this packet (TCP, UDP, ICMP, etc.)
- Destination IP: The target IP of this packet
- Destination Port: The target port of this packet
- State: This parameter evaluates if the sender of this packet already has a connection established, or if it is a new connection (can have different rules for the two cases)
- Action: The previous parameters classify a certain packet. The action parameter will indicate whether packets that fall into this classification should be accepted or dropped
A firewall will have a set of these rules, that will determine its behavior during packet analysis. Let's consider the following example: Imagine we are an organization, with a LAN for employees connected to the internet. In that LAN, we also have our web server running, that should be accessed by our clients through the Internet. If we have a firewall between the Internet and the LAN, the rule set might be something like this:
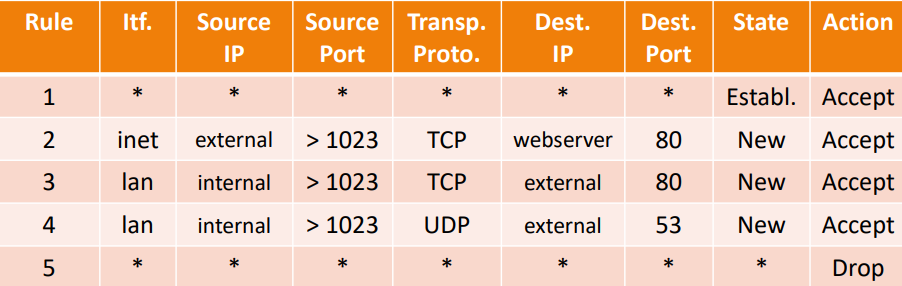
Fig.2: Example of a firewall rule set
- We allow every established connection to go through with Rule 1
- We allow external users to access the web server via HTTPS (TCP, port 80) with Rule 2
- We allow our employees to access external HTTPS servers with Rule 3
- We allow DNS requests from our employees with Rule 4
- Every other type of connection attempt is dropped with Rule 5
Bear in mind that the firewall analyzes the rules from the top to the bottom; therefore, we can have the rule to drop all packets in the last position and it doesn't affect the other rules
Generally, firewalls are more strict about incoming TCP and UDP traffic than outgoing traffic for these protocols, allowing for employees to still access external applications. Firewalls should also any malformed TCP and UDP requests (to prevent, for example, scan attacks).
Placement
We will now discuss where should we should place the firewall, and how can we design the local network to make it more secure. The firewall is usually running in a machine dedicated to itself, and it will be placed between a more trusted subnet and a less trusted subnet.
DMZ (DeMilitiarized Zone)
A DMZ is a part of the network (subnet) that doesn't belong to the LAN, and is generally less secure than the LAN; however, we still keep some control over it (unlike the internet). We generally want to put web servers inside DMZ's, because they are more likely to suffer attacks, but we don't want to compromise the LAN, and we can still implement security in the DMZ.
Core Topologies
We will present two ways arranging an organization's network that provides web services:
Core Topology 1: Dual-homed host
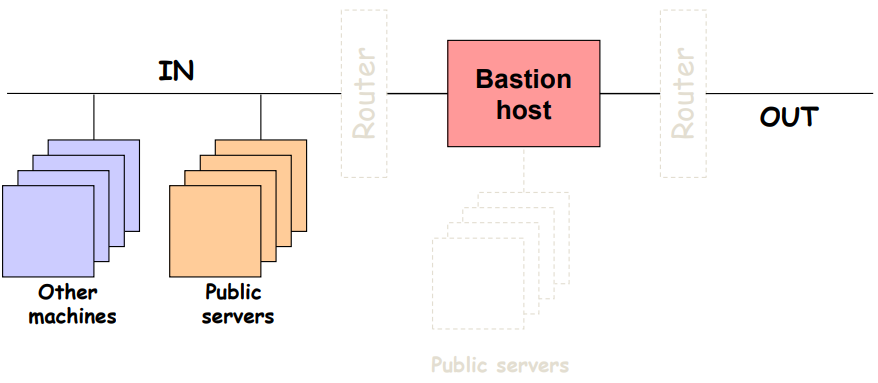
Fig.3: Example of a dual-homed host topology
There is a single firewall (bastion host), separating the two existing subnets: OUT and IN (where the local machines and web servers are placed)
-
Advantages:
- Simple and easy to manage
- Resource economy
-
Disadvantages:
- A single machine has to analyze all the traffic (traffic analysis is expensive!)
- If we want to expose the web servers, the firewall is of no use
- No separation between protected network and public servers
Core Topology 2: Screened Subnets
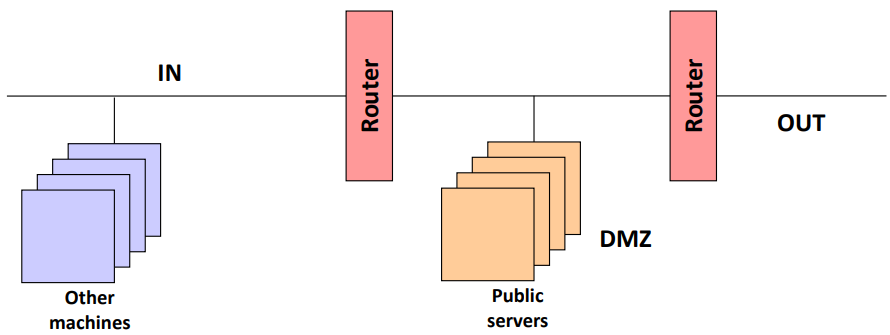
Fig.4: Example of a screened subnets topology
In this case the routers will do the packet filtering, and we will have two of them: one between the OUT subnet and the DMZ, and another between the DMZ and the IN network. Public servers are placed in the DMZ, and local machines in the protected network.
- Advantages:
- Public servers are now separated from the protected network
- Lower risk regarding a firewall being compromised
- Disadvantages:
- Lower control over the activities in the DMZ
If network isolation is possible through network virtualization, it might be a good option to consider several DMZ's, one for each type of server, to from several "layers" of security
Firewall Implementation on Linux (iptables)
To implement a packet-filtering firewall on Linux hosts, a program that is commonly used is iptables. Iptables is a program that uses the framework netfilter: a Linux framework for packet filtering.
To understand iptables, there are three important concepts that we need to know: tables, chains and rules. The way these are correlated is the following:
- Tables contain chains
- Chains contain rules
There are three different tables in iptables: NAT (for natting), Mangle (used to arbitrarily modify packets) and Filter (the one used for our purpose, firewall configuration).
Filter Table
The filter table has three chains:
- OUTPUT chain, corresponds to packets that are originated by a local process in the host, and are directed to the outside
- INPUT chain, corresponds to packets that are originated from outside the host, and are directed at the host
- FORWARD chain, which corresponds to packets originating from outside the host, and are meant to be forwarded to another machine
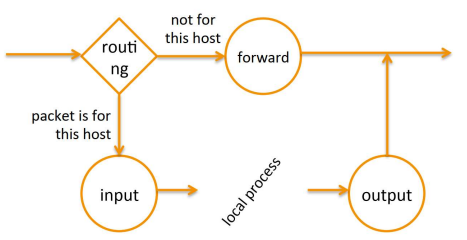
Fig.5: Flowchart of how packets can be assigned to different chains
All packets being filtered by this firewall will fall into one of these there categories, and will then be treated (accept or drop) according to the rules that have been set.
Additional material on iptables can be found here.
Stateful vs Stateless Firewalls
Like we saw in the packet filtering chapter, a firewall can decide to drop or accept packets based on the state of the connection of the two machines that are communicating. A good example of this is TCP sessions: before starting a conversation, there needs to be a three-way handshake (SYN, SYN-ACK, ACK), making it easy to record which machines have an established connection. For UDP, there is no such mechanism, but we can still approximate a connection through patterns and the addresses and ports of the packets.
Now, for keeping track of existing connections, the firewall will need to keep some type of state. This means we will have firewalls that keep track of state (stateful); and others that don't (stateless).
- Stateful firewalls: Keep track of previously established connections
- NEW and ESTABLISHED in the "state" rule field
- Stateless firewalls: Analyze each packet independently
- They can still decide whether it's a new connection or not based on packet content and flags
There advantages and disadvantages to the two types of firewalls. Stateful firewalls have the downside of being more expensive to run (due to memory consumption), but have the upside of requiring fewer rules to setup. On the other hand, stateless firewalls are less expensive to run, but require more rules.
The performance of a firewall is directly linked to the number of rules (less rules is better). Therefore, the choice between a stateful or a stateless firewall should be done according to your security policy.
- If our policy only requires a small set of rules, a stateless firewall might be more appropriate
- If more rules are needed, it might be better to use a stateful firewall, due to it requiring less rules
An additional advantage of using the least amount of rules to setup a firewall is to reduce the likelihood of configuration errors
Firewall Types
All of the firewalls seen previously have been of one type: Packet Filters. However, there are two additional types of firewall: Circuit-Level Gateway and Application-Level Gateway. We will now take a closer into them.
Circuit-Level Gateway
A circuit-level gateway usually operates in the transport layer (ex., TCP). In this type of firewall, a client application no longer communicates directly with the server, but will instead communicate with the gateway, which will act as a relay between the client and the server. The standard protocol for circuit-level gateways is SOCKS (SOCKets Secure).
SOCKS
SOCKS is a circuit-level gateway standard for, running on a UNIX server, comprised of three components:
- SOCKS Server: running in the firewall machine
- SOCKS Client Library: running on the hosts protected by the firewall
- SOCKS-ified versions of client programs: altered versions of protocols normally used, like FTP, TELNET,...
In SOCKS, a client will initiate a connection to the SOCKS Server (TCP, port 1080) and will negotiate the authentication method and authenticate itself. Then, every time the client needs to send a request to the server, it will send a relay request to the SOCKS Server; it is then that the SOCKS Server will act as a firewall, either deciding to drop or accept the request. If accepted, the request will be relayed to the server, and its response will then be sent to the client.
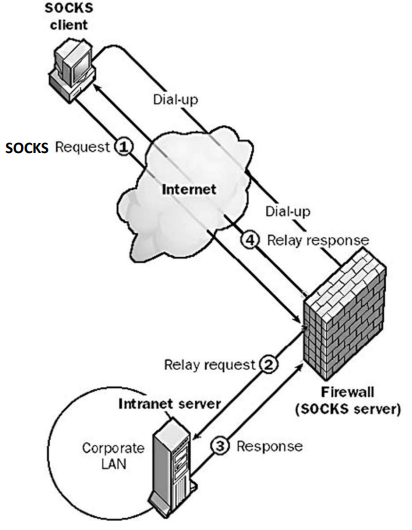
Fig.6: Diagram of SOCKS's architecture
Application-Level Gateway
Application-level gateways operate on the application layer, analyzing and modifying packets' content. Typically, this firewall is running in a proxy server, and typically there is a proxy for each protocol. Some characteristics of the proxy operation are:
- User-oriented access control
- Packet content analysis and modification
- Detailed logging of ongoing operations
- Caching: keeps copies of frequently requested data
Comparison between firewall types
Packet Filter:
- Faster but harder to configure
- Cannot control 'misbehaving' protocols (for example, ftp)
- Stateless does not consider previously sent packets
Application-level gateways:
- Slower but easier to configure
- Can make rules independently for each protocol
- Allows for authentication mechanisms
- Less adaptable to new protocols
Circuit-level gateways are not present here because, other than the fact that they operate in the Transport layer, they are very similar to the application-level gateways, and end up having the same upsides/downsides.
Issues with firewalls
There are some known issues with firewalls, like:
- Exploring open ports: There is almost always a port open, for example port 80 for HTTP requests. There are many attacks that use this port
- IP Spoofing: An attacker can cover its IP address with another one (spoofing), making it impossible for firewalls to know the true source IP
- If we are using an application-level gateway, each protocol has to have its gateway
- Depending on the rules setup, there is always the tradeoff between security and communication with outside world.
- There are attacks that can bypass a firewall (for example, dial-up link, wireless, cellular router, ...)
- Firewalls do not protect from attacks inside the protected network (for example, an employee might bring his personal USB drive, already infected with some type of virus)
Intrusion Detection Systems (IDS)
IDSs are systems designed to monitor a particular network or host, log activity and report about suspect behavior that might be an attack on the system it is protecting. There are both passive IDSs (only notify about potential attacks) and active IDSs (can take action to mitigate attack).
Why use an IDS
In the previous chapter, we saw how firewalls can prevent attacks, so why should we need an IDS? The truth is that, for any given system, no matter how secure it is and how many security systems there are, there will always be vulnerabilities (can either be known or unknown). Therefore, an IDS is a good complimentary system to a firewall, in the sense that if a firewall fails to prevent an attack, an IDS can detect it and take appropriate measures.
When prevention fails, an IDS can be a valuable tool. Some of the advantages of using an IDS are:
- Detect ongoing external intrusions
- Detect preliminary phases of attacks
- Detect intrusion from an internal source (malicious staff, phishing, etc.)
- It is a bigger concern due to less strict security policies for accesses from inside the protected network
- Gather information to help prevention against future attacks
- Verify effectiveness of prevention mechanisms
- Document existing threats
IDSs can obtain information, not only through network monitoring and packet examination, but also looking at sensible information being altered (for example, multiple changes to a password database). Because of this, IDSs can help detect:
- Preliminary phases of attacks (probes, for example port scans)
- Attacks coming from outside source (for example, DDOS)
- Attacks coming from internal source (for example, virus in employee's computer connected to company LAN)
Firewall vs IDS
We will now make a comparison between firewalls and IDSs:
Firewall:
- Acts through packet-filtering (looks at IP/TCP/UDP headers)
- Do not look into packets, nor create correlations between packets
IDS:
- Deep Packet Inspection (DPI):
- Can take a closer look at packet's content, and compare it to database of known attacks
- Can make correlations between packets (detect incoming DDOS attacks, port scanning, etc.)
Attack Detection
Like we saw, IDSs detect attacks through packet inspection, correlation and comparison with known patterns. Once an attack is detected, an alarm is generated. The amount of alarms generated will depend on the IDS configuration: a stricter policy will generate more false positives, while a looser one will generate more false negatives.
False Positive: The system reported an attack, but in reality it didn't exist
False Negative: The system didn't detect an attack, but in reality there was one
Honeypots
An IDS can also leverage the use of a honeypot. Honeypots are systems designed to be vulnerable, and to deceive the attacker into thinking that he can obtain something of value from them, when in fact it's sole purpose is to attract attackers. The objectives of honeypots are:
- Deceive an attacker from the true system
- Gather information about potential attacks
- Gather forensic information
It has a possible downside: honeypots can also be used by attackers as attack origins.
IDS Classification
In this chapter we will look into possible different categories of how an IDS can function differently.
Detection Method
(TODO)
Additional Content
iptables
These are all of the tables' chains:
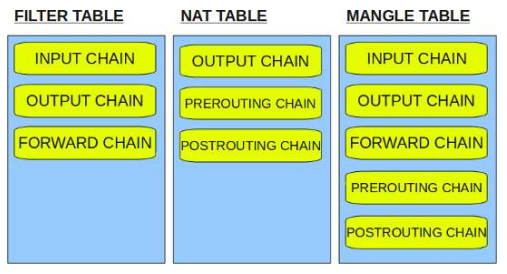
Fig.7: All of the tables' chains in iptables
This table represents the flow of one packet in iptables, passing through the several tables/chains:
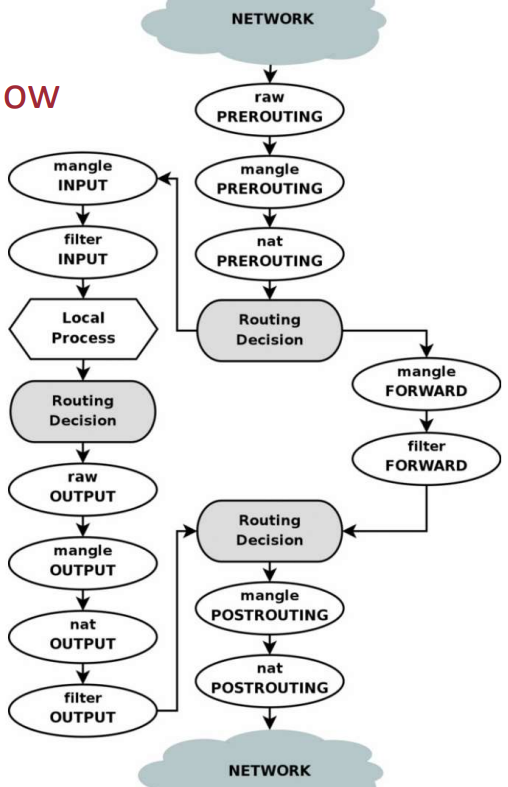
Fig.8: Flow of a packet in iptables